


Tu as l’impression que l’IA te comprend et te parle, en fait, elle ne comprend rien.
Dans cet article, tu vas voir que la Tokenisation et encastrements vectoriels sont les premières étapes du calcul de la sémantique pour les LLM.

Lorsqu’une IA générative semble te répondre comme un humain, ça n’a rien à voir avec de l’intelligence, ni de l’empathie, ce sont simplement des calculs froids et désincarnés. Pour que les LLM puissent traiter le langage naturel, la phase initiale implique la conversion des mots en chiffres, matérialisés comme des coordonnées dans un espace donné. Si cela te semble obscur, rassure-toi, moi aussi. 😅
Mais j’ai tenté de comprendre. Je te livre les fruits de mes recherches.
Pourquoi est-ce important ?
Parce que tu ne pourras jamais réellement bien utiliser l’IA si tu n’as pas un minimum de compréhension de son fonctionnement.
Commençons par la tokenisation.
Qu’est-ce qu’un token en NLP (Traitement du Langage Naturel) ?
La “tokenisation” en traitement du langage naturel n’a rien à voir avec le tokenism à la sauce South Park ou les tokens à la sauce Web3.
Ici, la tokenisation consiste à représenter un mot, une partie d’un mot ou un caractère par un chiffre.

Les algorithmes modernes, comme BPE (Byte Pair Encoding) ou WordPiece, décomposent les mots en sous-unités en fonction de leur fréquence dans un corpus, et non selon des critères linguistiques.
Ces sous-unités ne sont pas toujours significatives pour un humain, mais elles permettent aux modèles informatiques de représenter efficacement les mots. Par exemple :
- "chanter" → "chant-" et "-er"
- "chantant" → "chant-" et "-ant"
- "efficace" → "effic-" et "-ace"
- "efficacité" → "effic-" et "-acité"
Dans ces cas, "chant-" ou "effic-" ne sont pas nécessairement des morphèmes au sens linguistique (une racine comme "chant-" peut l'être, mais "effic-" est juste une séquence fréquente). Ces sous-unités sont choisies pour leur fréquence dans le corpus, ce qui permet de réduire la taille du vocabulaire tout en capturant des motifs récurrents.
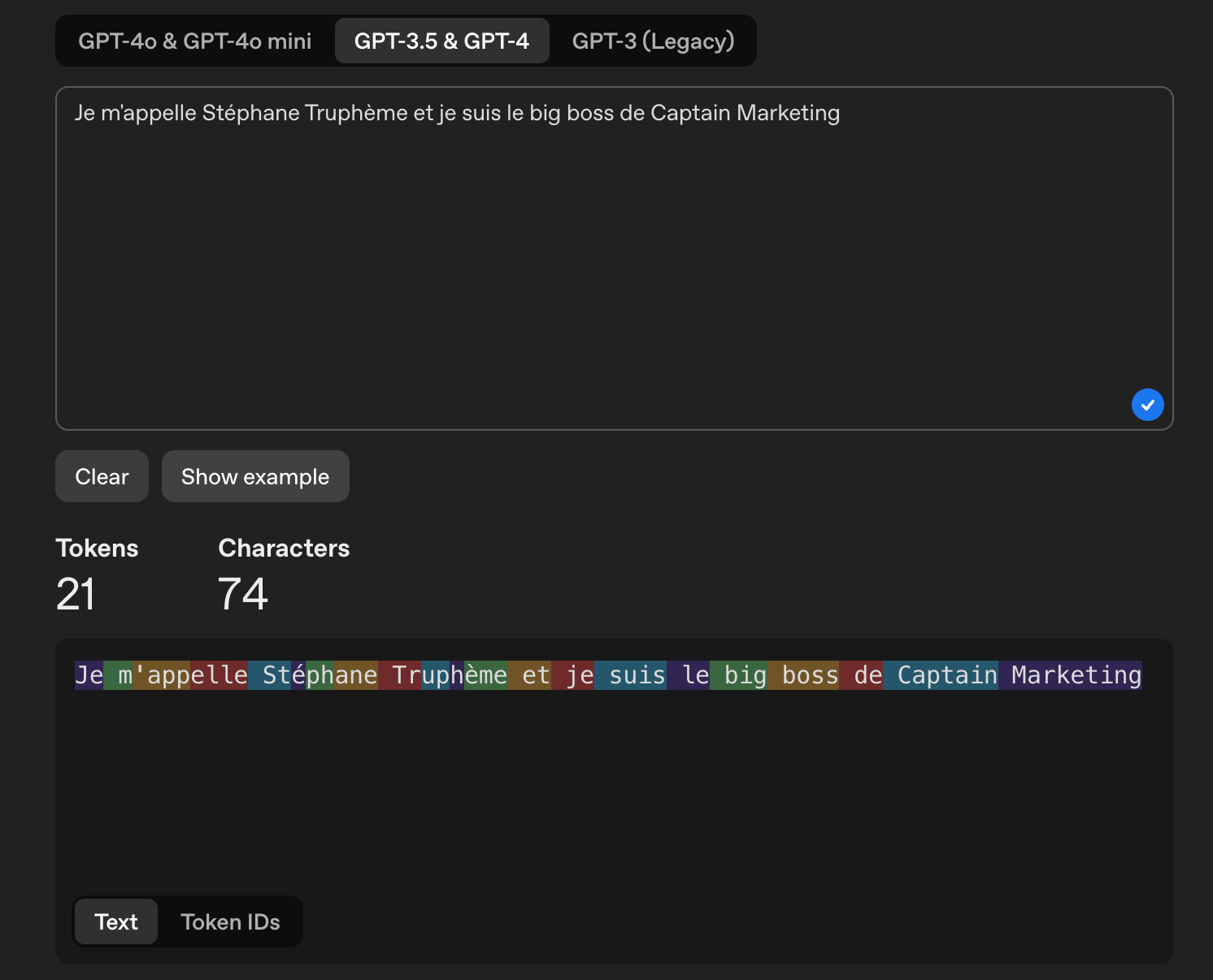
Sur cette capture d’écran, nous voyons comment le LLM a décomposé la phrase en tokens. Chaque couleur représente un token. Par exemple, m’appelle a été découpé en 3 tokens : m’ - app - elle.
Tu peux faire l’expérience toi-même sur : https://platform.openai.com/tokenizer
Chaque sous-unité est associée à un identifiant numérique (un token) dans le vocabulaire du modèle. Par exemple :
- "chant-" = 54321
- "-er" = 1234
- "-ant" = 5678
Ainsi, "chanter" devient [54321, 1234] et "chantant" devient [54321, 5678]. Ces identifiants numériques sont utilisés par le modèle pour apprendre des relations sémantiques à partir des données, sans que les sous-unités elles-mêmes aient un sens intrinsèque.
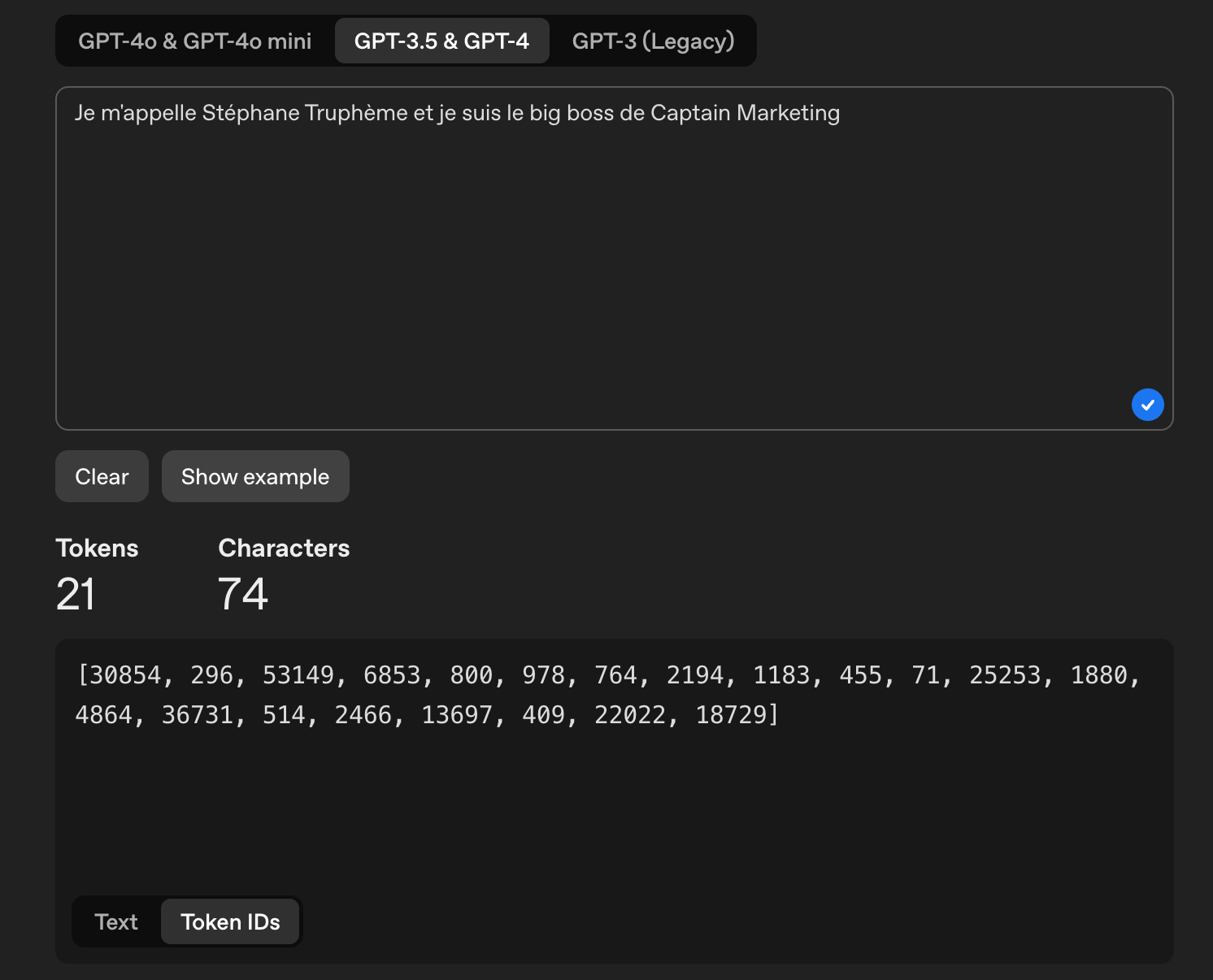
Dans cette capture d’écran, nous voyons comment le LLM a attribué à chaque token un chiffre. Tu peux faire l’expérience toi-même sur : https://platform.openai.com/tokenizer
Les identifiants numériques sont des sortes de compromis entre caractères et mots entiers :
- Découper les mots en caractères individuels (comme "c", "h", "a", "t" pour "chat") permet une granularité maximale, mais cela génère des séquences très longues, ce qui augmente la complexité computationnelle et rend difficile la capture des relations sémantiques entre les unités.
- À l'inverse, utiliser des mots entiers est intuitif. Mais cela pose un problème pour les langues à forte flexion (comme le français, avec ses conjugaisons et déclinaisons) ou pour les mots rares. Cela peut aussi limiter le vocabulaire du modèle, car chaque variante d'un mot (ex. : "manger", "mange", "mangeant") serait un token distinct.
En découpant en sous-unités (tokenisation par morceaux) : "mange##ant", "##er" pour "manger"), la tokenisation trouve un équilibre. Elle réduit le nombre de tokens tout en capturant les structures récurrentes des mots, ce qui est plus efficace pour l'apprentissage des modèles.
En conclusion, la tokenisation découpe les mots en “morceaux utiles” (ou sous-unités, comme des sous-mots ou des morphèmes) pour que leurs relations puissent être calculées mathématiquement.
Comme nous venons de le voir, on pourrait découper en mots entiers ou en caractères, mais ce n’est pas optimal.
Voici quelques avantages de la “découpe des mots en “morceaux utiles” :
Gestion des mots rares et nouveaux :
- Les mots rares, composés ou néologismes (ex. : "anticonstitutionnellement") ne figurent pas toujours dans un vocabulaire fixe. En découpant en sous-unités (ex. : "anti##constitu##tion##nel##lement"), le modèle peut recomposer ces mots à partir de morceaux connus, même s'il ne les a jamais vus entiers.
- Cela améliore la généralisation, surtout pour les langues agglutinantes (comme le turc ou le finnois) où les mots sont formés par l’ajout de nombreux suffixes.
Efficacité computationnelle :
- Les modèles de langage (comme ceux basés sur les “transformers”) traitent des séquences de tokens avec une limite de longueur. Les sous-unités réduisent la longueur des séquences par rapport à un découpage par caractères, tout en conservant plus d'informations sémantiques qu'un découpage par mots entiers. Par exemple, "internationalisation" peut être découpé en ["inter", "##nation", "##alisation"] plutôt que 20 caractères ou un seul mot, ce qui optimise la mémoire et le calcul.
Adaptabilité aux langues :
- Certaines langues, comme le chinois ou le japonais, n'ont pas de délimiteurs clairs entre les mots. La tokenisation par sous-unités permet de gérer ces cas en identifiant des unités fréquentes dans le texte, sans dépendre de la notion de "mot".
- Pour le français, elle gère bien les contractions (ex. : "l’" ou "qu’") et les formes verbales variées.
Des algorithmes comme Byte Pair Encoding (BPE) ou WordPiece construisent un vocabulaire de sous-unités en analysant les fréquences dans un corpus. Ils commencent par des caractères, puis fusionnent les paires les plus fréquentes pour créer des tokens plus grands (ex. : "in" + "g" → "ing"). Cela crée un vocabulaire compact qui couvre efficacement les motifs récurrents.
Par exemple, dans BPE, "chat" pourrait être un token unique parce que le mot est fréquent, mais "anticonstitutionnellement" serait divisé en sous-unités moins fréquentes.
En résumé, la tokenisation par morceaux est un compromis optimal : elle réduit la taille du vocabulaire, améliore la gestion des mots rares ou nouveaux, et s’adapte à la diversité des langues tout en restant efficace pour les modèles d’apprentissage automatique.
Ce qu’il faut retenir : la tokenisation, c’est l’étape clé où le texte est découpé en petits morceaux, les tokens, pour former le vocabulaire des modèles de langage (LLM). Ces modèles s’entraînent sur des milliards de tokens, et des algorithmes comme BPE, WordPiece ou SentencePiece regroupent les sous-unités les plus fréquentes pour rendre ce vocabulaire plus compact et efficace.
Tu as peut-être déjà remarqué qu’une IA s’arrête nette ou te demande de patienter si tu le bombardes de texte : c’est parce que tu as atteint sa limite de tokens !
Des tokens aux vecteurs : comment les ordinateurs comprennent le sens des mots ?
Ok, mais les tokens ne nous disent pas exactement comment les algorithmes comprennent le sens des mots. Il faut ici ajouter une autre notion : les encastrements vectoriels !

Comment fonctionnent les encastrements vectoriels pour les LLM
Les encastrements vectoriels transforment des données complexes en vecteurs multidimensionnels, rapprochant les points de données similaires.
Ces vecteurs facilitent diverses applications, telles que la recherche sémantique, les moteurs de recommandation et la recherche de similarités d'images.
En comparant et en récupérant des encastrements similaires dans une base de données vectorielle, ces systèmes peuvent traiter les données en tenant compte des relations, du sens et du contexte réels.
Ces encastrements vectoriels sont comme des “fiches numériques” (les codes uniques) qui décrivent chaque token. Ces codes sont organisés dans un grand classeur invisible où les tokens ayant des significations proches sont regroupés.
Imagine un immense classeur où chaque token a sa fiche. Par exemple :
- Dans la phrase "La réunion était productive", les tokens comme "productif" et "efficace" ont des fiches très similaires, car ils parlent d'idées proches.
- Dans "Nous optimisons notre travail efficacement", "efficacement" est aussi proche de "productif" dans ce classeur numérique.
Grâce à ces fiches, l’ordinateur comprend que les deux phrases parlent d’améliorer le travail, même si les mots changent.
En résumé, les encastrements vectoriels aident l’ordinateur à relier les tokens selon leur sens, comme dans un “grand classeur de significations”. Mais pour vraiment saisir une phrase, il faut des modèles qui utilisent le contexte, car les encastrements seuls peuvent se tromper avec des mots à sens multiples !
Le contexte : là où les “encastrements vectoriels” montrent leurs limites
Mais parfois, ça se complique.
Regarde cet exemple :
- "Je dépose de l'argent à la banque." (une institution financière)
- “La banque d’organes sauve des vies.” (un stock médical d’organes)
Ici, le mot "banque" apparaît dans les deux phrases, mais il n'a pas du tout le même sens. Les encastrements vectoriels galèrent avec la polysémie, quand un mot a plusieurs sens. "Banque" aurait le même encastrement, alors que son sens change complètement selon le contexte.
Les encastrements seuls ne suffisent donc pas à comprendre les relations complexes qui créent le vrai sens du langage. Word2Vec a été une belle avancée, mais ne capte que les relations superficielles.
Pour gérer ces différences de sens selon le contexte, les chercheurs ont inventé un mécanisme capable de différencier les contextes. Cette invention, qui vient aussi de chez Google, c'est le transformer dont on parlera prochainement.
Je te conseille de lire la suite de cet article ici 👇

Abonne-toi si l’IA t’intéresse.
Quelques liens pour aller plus loin :




